
AI不是只有4090、A800这些卡, 英伟达RTX 5000 Ada工作站也能跑AI
预算有限情况下,能自由地在工作站上跑AI的感觉还是很好的。
过往知道4090可以跑AI,预算充足的情况下可以上NVIDIA Tesla显卡,但是服务器资源有限,我们最近就直接用新到手的英伟达 RTX 5000 Ada 搭到自己工作站上做了个升级,这样方便在办公室自由地跑跑推理和模型微调。最近主要测试了跑跑llma3。
以下就是我们用RTX 5000 Ada 工作站测试当红大模型llma3的情况:
测试环境:
软件平台:系统:Ubuntu22.04;架构: VLLM/Transformer;
测试的模型:Llama3-8B,使用AWQ量化的Llama3-8B,使用GPTQ量化的Llama3-70B。
测试用例两种模式:
一种是对话模式,就是说我们输入比较少生成的一个数量恰中的一个水平,我们这里用的是32个token的输入以及生成256个输出的一个情况。
另一种是检索模式,输入1K tokens,输出256 token。这个是较为典型的RAG用例,即检索增强生成。
测试参数:
1、Throughput:吞吐率,单位为token/s,即每秒生成的token数量。对于中文字符来说,可以认为是每秒生成的字数。
2、Latency:时延,在我们做大模型推理的时候,从输入到所有输出生成完毕的所需时间,单位为秒。
3、AWQ/GPTQ:大模型的量化技术,普遍使用4bit的方式来代表原本16bit的浮点数,可以大大节省对显存的占用率,同时提高推理速率。
4、Batch size,我们在做大模型推理的时候,可以并发输入大模型里面的用户请求的数量,一般来说我们的并发数量越大,吞吐率越高。但过大的批量,会导致时延大大加长,适得其反。所以需要取值适中。
测试过程及结果:
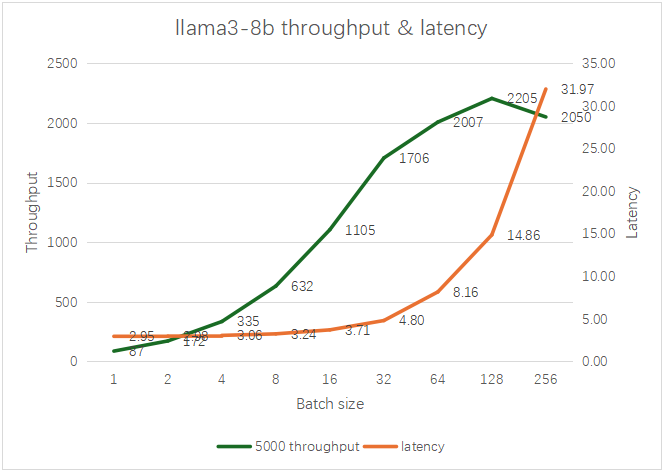
1、单卡5000 Ada 测试AWQ量化的Llama3-8B。
当batch size 达到128时,能达到最大的吞吐率,为2205 t/s,即每秒可输出2205个Token,时延小于15秒。比较理想的batch size是32-64。
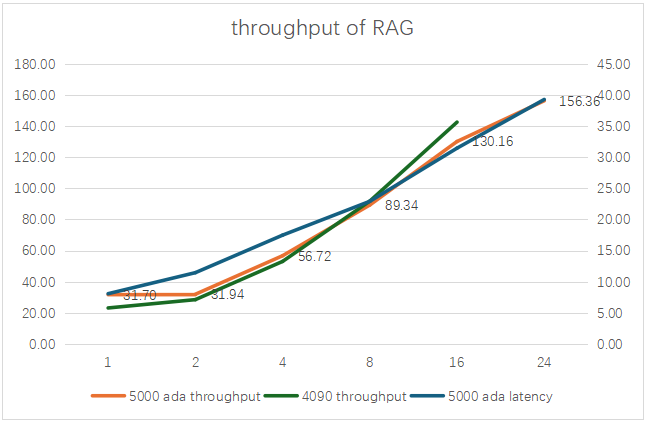
2、单卡5000 Ada 测试Llama3-8BRAG。
当batch size 达到24时,能达到最大的吞吐率约156 t/s,其时延约39秒。对比过去测试单卡4090 的性能来看,4090单卡最大只能加载到16个请求。
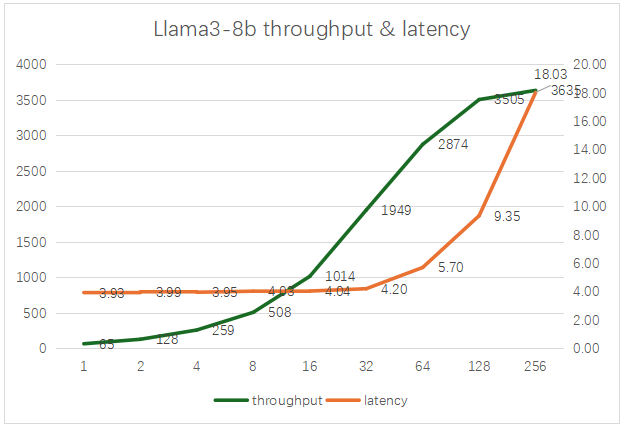
3、4卡5000 Ada 测试AWQ量化的Llama3-8B
当batch size 达到256时,能达到最大的吞吐率3635 t/s,其时延约为18秒。比较理想的batch size是32-128。
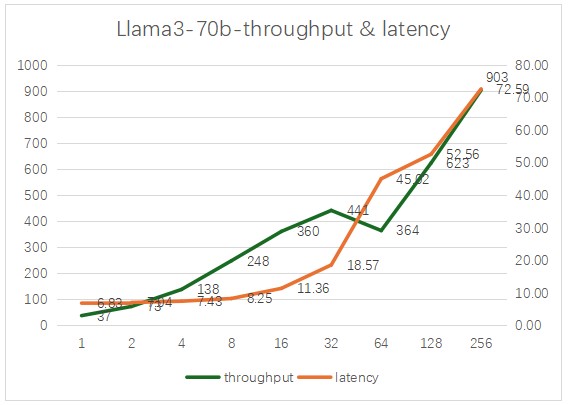
4、4卡5000 Ada 测试GPTQ量化的Llama3-70B
当batch size 达到256时,能达到最大的吞吐率903 t/s,其时延约为72秒。建议batch size控制在32以内。
总体感受不错,毕竟预算有限,还能自由地在工作站上跑跑AI的感觉还是很好的。
(外观参数等可参照:https://www.bilibili.com/video/BV1FN4y1f7wo/?share_source=copy_web&vd_source=9b60e49bb50bbcdce771cafe00e5dca5

最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 Ubuntu
显卡
服务器
测试
用户
Ubuntu
显卡
服务器
测试
用户