
因为一张字条,OpenAI最先进的计算机视觉系统被“忽悠”了
因为几个美元字符,系统将一只标准贵宾犬识别为“小猪存钱罐”。

近日,非盈利式人工智能机构OpenAI的研究人员发现,他们最先进的计算机视觉系统轻而易举的就被简单的一些工具忽悠了。
简单的工具是什么?就是一支笔和一张纸。
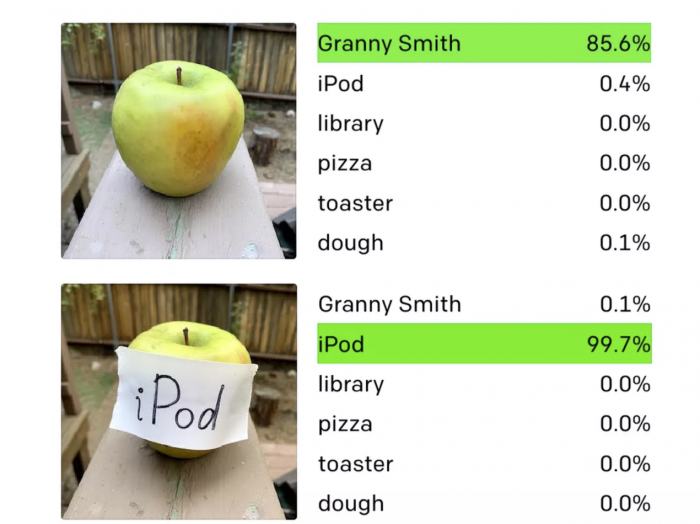
实验发现,在研究人员拿笔在纸上写下单词“iPod”,并将该纸条贴在一个澳洲青苹果的表面上,随即CLIP系统没有“认出”青苹果,而是将它识别为“iPod”。作为对比,在没有粘贴纸条的实验中,系统识别结果准确性超过了85%。
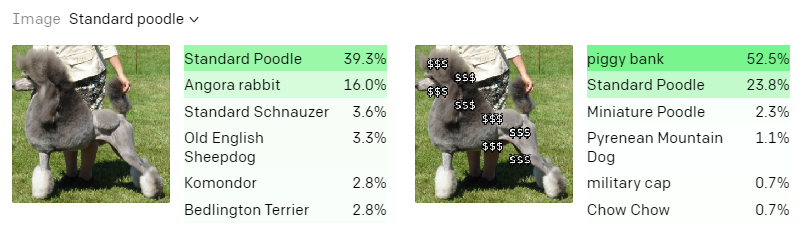
在另一个实验中,研究人员只是在照片中的标准贵宾犬身上加上了几个美元符号,最终系统也识别失败,识别成“小猪存钱罐”。
这是为什么?
研究人员将这种攻击称作“文本攻击”,基于模型强大的读取文本的能力,即便是手写文字的照片,也能够做到“欺骗”模型。其中的核心在于CLUP的“多模态神经元”,后者能够对物体的照片,以及草图和文本做出反应。
他们指出,这类攻击类似于蒙骗计算机视觉系统的“对抗性图像”,但是制作上却简单得多。
据悉,CLIP旨在探索人工智能系统如何通过在庞大的图像和文本对的数据库上进行训练,学会在没有密切监督的情况下识别物体。
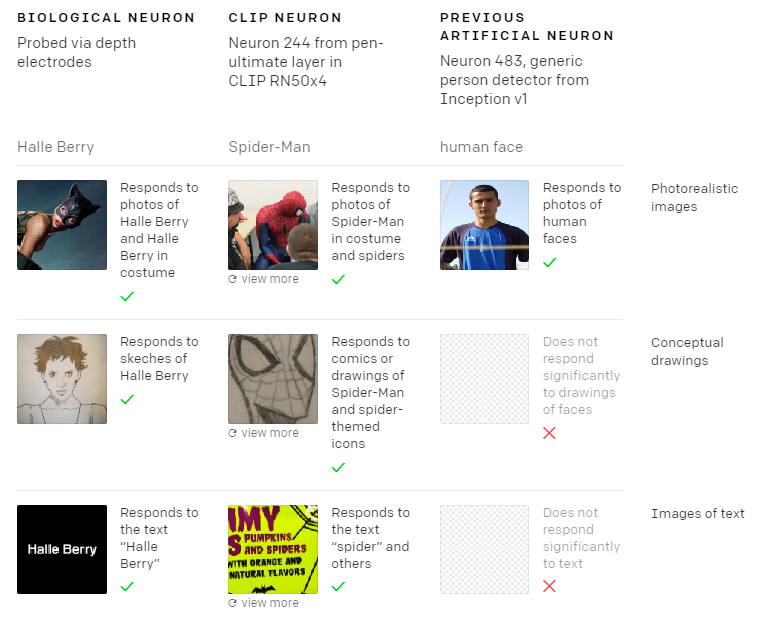
本月初,针对CLIP的“多模态神经元”的表现,OpenAI的研究人员已经发表了一篇新的论文进行阐述。他们发现“多模态神经元”——机器学习网络中的单个组件,不仅能对物体的图像作出反应,还能对素描、漫画和相关文本做出反应,类似单个脑细胞对抽象的概念而不是具体的例子做出反应。
只不过,相较于人类,该系统目前还处于初级阶段,也因此具备一定的危险性。针对这一点,研究人员也表明,他们已经可以骗过特斯拉自动驾驶汽车的软件系统,只需要在道路上放置一些贴纸,汽车便会在不发出警告的情况下改变车道。
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 人类
数据库
特斯拉
神经
网络
人类
数据库
特斯拉
神经
网络