
【重磅】谷歌发布 Zero-Shot 神经机器翻译系统:AI 巴别塔有望成真
系统可以实现“零数据翻译”,即能够在从来没有见过的语言之间进行翻译,这意味着传说中的“巴别塔”有望成真。
【导读】谷歌今日更新博客,介绍了谷歌神经机器翻译系统重大更新,实现了用单一模型对多语种通用表征。这种新的模型体积不仅与多语言翻译模型一样,参数相同,而且速度更快、质量更高。不仅如此,系统还实现“零数据翻译”,也即能够在从来没有见过的语言之间进行翻译。这意味着传说中的“巴别塔”有望成真。
过去10年中,谷歌翻译已从仅支持几种语言发展到了支持 103 种,每天翻译超过了 1400 亿字。为了实现这一点,我们需要构建和维护许多不同的系统,以便在任何两种语言之间进行转换,由此产生了巨大的计算成本。神经网络改革了许多领域,我们确信可以进一步提高翻译质量,但这样做意味着重新思考谷歌翻译背后的技术。
今年 9 月,谷歌翻译改为启用谷歌神经机器翻译(GNMT)的新系统,这是一个端到端的学习框架,可以从数百万个示例中学习,并在翻译质量方面有显著提升。不过,虽然启用 GNMT 的几种语言翻译质量得到了提升,但将其扩展到所有 103 种谷歌翻译支持的语种,却是一个重大的挑战。
实现零数据翻译(Zero-ShotTranslation)
在论文《谷歌多语言神经机器翻译系统:实现零数据翻译》(Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation)中,我们通过扩展以前的 GNMT 系统解决这一挑战,使单个系统能够在多种语言之间进行翻译。我们提出的架构不需要改变基本的 GNMT 系统,而是在输入句子的开头使用附加的“token”,指定系统将要翻译的目标语言。除了提高翻译质量,我们的方法还实现了“Zero-Shot Translation”,也即在没有先验数据的情况下,让系统对从未见过的语言进行翻译。
下图展示了最新 GNMT 的工作原理。假设我们使用日语和英语以及韩语和英语之间相互翻译为例,训练一个多语言系统,如动画中蓝色实线所示。这个新的多语言系统与单个 GNMT 系统大小一样,参数也一样,能够在日英和韩英这两组语言对中进行双语翻译。参数共享使系统能够将“翻译知识”(translation knowledge)从一个语言对迁移到其他语言对。这种迁移学习和在多种语言之间进行翻译的需要,迫使系统更好地利用其建模能力。
由此,我们想到:能够让系统在从未见过的语言对之间进行翻译吗?例如韩语和日语之间的翻译,系统并没有接受过日韩之间翻译的训练。但答案是肯定的——虽然从来没有教过它但,新的系统确实能够生成日韩两种语言之间合理的翻译。我们将其称为“零数据”(zero-shot)翻译,如动画中的黄色虚线所示。据我们所知,这还是首次将这种类型的迁移学习应用机器翻译中。
零数据翻译的成功带来了另一个重要的问题:系统是否学会了一种通用的表征,其中不同语言中具有相同意义的句子都以类似的方式表示,也即所谓的“国际通用语”(interlingua)?使用内部网络数据的三维表征,我们能够看见系统在翻译日语、韩语和英语这几种语言时,在各种可能的语言对之间进行转换(比如日语到韩语、韩语到英语、英语到日语等等)时,内部发生的情况。
上图中的(a)部分显示了这些翻译的总体几何构成。图中不同颜色的点代表不同的意思;意思相同的一句话,从英语翻译为韩语,与从日语翻译为英语的颜色相同。我们可以从上图中看到不同颜色的点各自形成的集合(group)。(b)部分是这些点集的其中一个放大后的结果,(c)部分则由原语言的颜色所示。在单个点集中,我们能够看到日韩英三种语言中,拥有相同含义的句子聚在一起。这意味着网络必定是对句子的语义进行编码,而不是简单地记住短语到短语之间的翻译。由此,我们认为这代表了网络中存在了一种国际通用语(interlingua)。
我们在论文中还写下了更多的结果和分析,希望这些的发现不仅能够帮助从事机器学习或机器翻译的研究人员,还能对于语言学家和对使用单一系统处理多语言感兴趣的人有用。
最后,上述多语言谷歌神经机器翻译系统(Multilingual Google Neural Machine Translation)从今天开始将陆续为所有谷歌翻译用户提供服务。当前的多语言系统能够在最近推出的16个语言对中的 10 对中进行转化,提高了翻译质量,并且简化了生产架构。
商业部署后,实现技术上的突破
正如前文所说,今年 9 月,谷歌宣布对部分语种启用谷歌神经机器翻译(GNMT)的新系统,并在几种率先使用的测试语种(包括汉语)翻译质量方面得到了显著提升。下面的动图展示了 GNMT 进行汉英翻译的过程。首先,网络将汉字(输入)编码成一串向量,每个向量代表了当前读到它那里的意思(即 e3 代表“知识就是”,e5 代表“知识就是力量”)。整句话读完之后开始解码,每次生成一个作为输出的英语单词(解码器)。
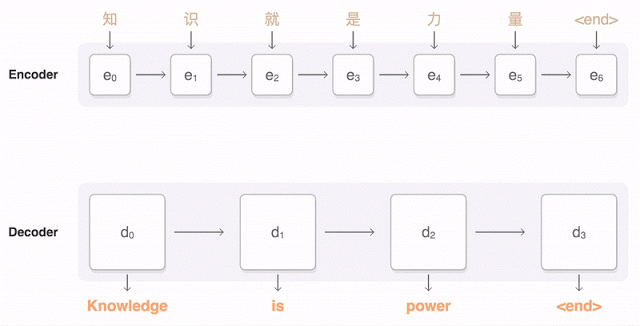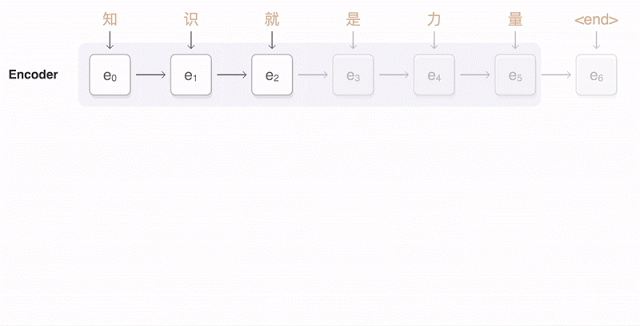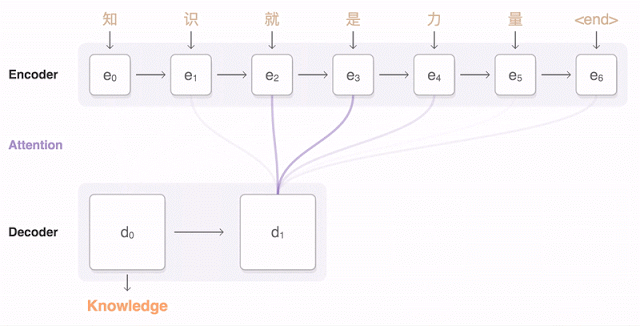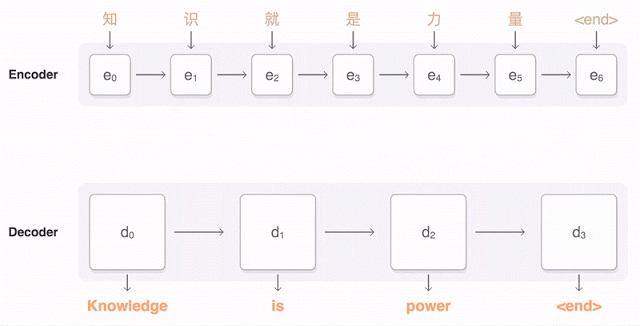
要每一步生成一个翻译好的英语单词,解码器需要注意被编码中文向量的加权分布中,与生成英语单词关系最为密切的那个(上图中解码器 d 上面多条透明蓝线中颜色最深的那条),解码器关注越多,蓝色越深。
使用人类对比评分指标,GNMT 系统生成的翻译相比此前有了大幅提高。在几种重要语言中,GNMT 将翻译错误降低了 55%-58%。
不过,当时也有很多研究人员认为,当时谷歌翻译取得的“里程碑”,与其说是技术突破,不如说是工程上的胜利——大规模部署本身确实需要软硬件方面超强的实力,尤其是想谷歌翻译这样支持 1 万多种语言的商业应用,对速度和质量的要求都非常的高。但是,神经机器翻译的技术早已存在,借鉴了语言和图像处理方面的灵感,是多种技术的整合。
现在,只用了大约 2 个月的时间(论文首次上传到 arXiv 是 11 月 14 日),谷歌翻译和谷歌大脑团队就实现了技术上的突破——让系统在从未见过的语言对之间进行翻译,也即所谓的“zero-shot translation”。
不仅如此,谷歌研究人员还在论文最后做了分析,新的模型代表了实现一种“国际通用语”模型的可能。有评论称,这可以说是实现“巴别塔”的第一步。
谷歌神经机器翻译系统架构
就在几天前,国外研究员 Smerity 在他的博客上发布了一篇分析谷歌神经机器翻译(GNMT)架构的文章,在 HackerNews、Reddit 等网站都引发了很多讨论。
Smerity 在博文中指出,GNMT 的架构并不标准,而且在很多情况下偏离主流学术论文中提出的架构。但是,根据谷歌特定的需求,谷歌修改了系统,重点保证系统的实用性而并非追求顶尖结果。
【论文】谷歌的多语言神经机器翻译系统:实现 zero-shot 翻译

摘要
我们提出了一种使用单一神经机器翻译(NMT)模型,在多语种之间进行翻译简洁而优雅的解决方案。不需要修改谷歌现有的基础系统模型架构,而是在输入句子的前面加入人工 标记(token)明确其要翻译成的目标语言。模型的其他部分(包括编码器、解码器和注意模型)保持不变,而且可以在所有语言上共享。使用一个共享的 wordpiece vocabulary,这种方法能够使用单一模型实现多语种神经机器翻译,而不需要增加参数,相比此前提出的方法更为简单。实验表明,这种新的方法大部分时候能提升所有相关语言对的翻译质量,同时保持总的模型参数恒定。
在 WMT' 14 基准上,单一多语言模型在英法双语翻译上实现了与当前最好技术相同的结果,并在英德双语翻译上超越当前最佳的结果。同时,单一多语言模型分别在 WMT'14 和 WMT'15 基准上,超越了当前最佳的法英和德英翻译结果。在用于生产的语料库上,多达 12 个语言对的多语言模型能够实现比许多单独的语言对更好的表现。
除了提升该模型训练所用的语言对的翻译质量之外,新的模型还能在训练过程中将没有见过的语言对相互联系起来(bridging),表明用于神经翻译的迁移学习和零数据翻译是可能的。最后,我们分析了最新模型对通用语言间表征的迹象,还展示了一些混合语言时会出现的有趣案例。
【编者按】本文转载自新智元。文章来源: Google Research。作者:Mike Schuster (Google Brain), Melvin Johnson (Google Translate) and Nikhil Thorat (Google Brain )。编译者:李静怡
最后,记得关注微信公众号:镁客网(im2maker),更多干货在等你!
 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技产业媒体
关注技术驱动创新
 Zero-Shot
人工智能
硬科技
谷歌
Zero-Shot
人工智能
硬科技
谷歌